

Drone Swarm Search: The Coverage Environment
About
The Coverage Environment is our second training environment, building on the PettingZoo framework and accommodating both multi-agent and single-agent setups with reinforcement learning algorithms. In contrast to the Search Environment, which aims to locate survivors, the Coverage Environment focuses on efficiently maximizing the search spread over the most probable area in minimal time. This environment differs from the Search Environment in its static nature; it employs a Lagrangian particle model that integrates real tidal data to accurately represent the area of highest probability. This simulation utilizes the open-source library Opendrift. Below, you can find a visual representation of the environment. To explore the environment without an algorithm, execute the script basic_coverage.py.
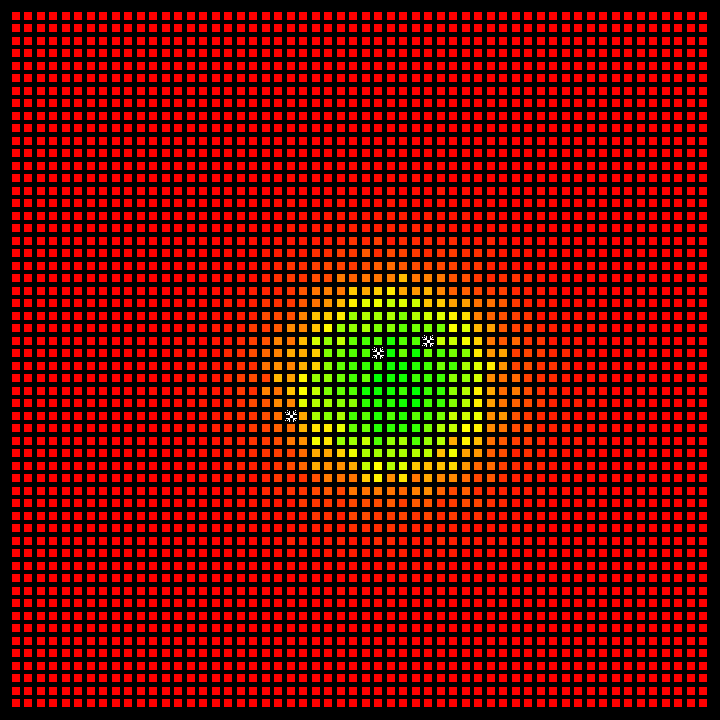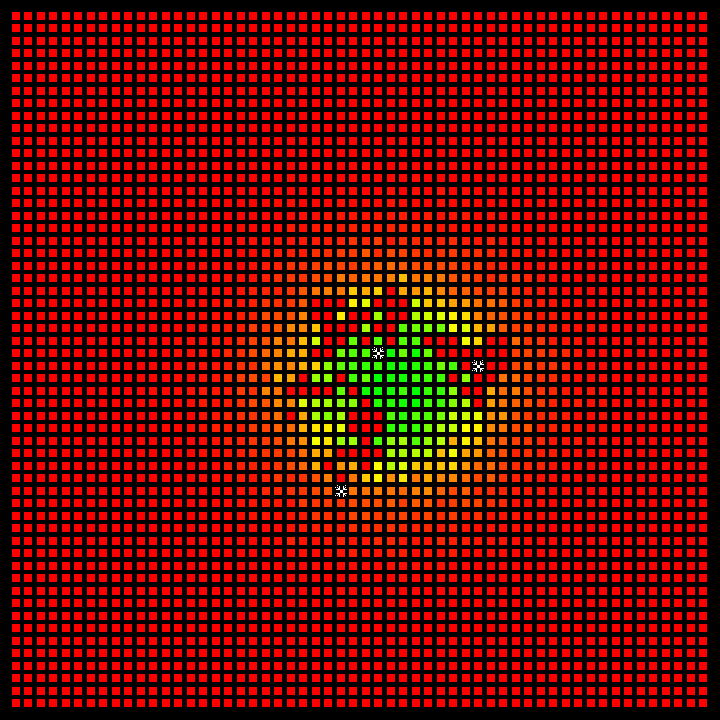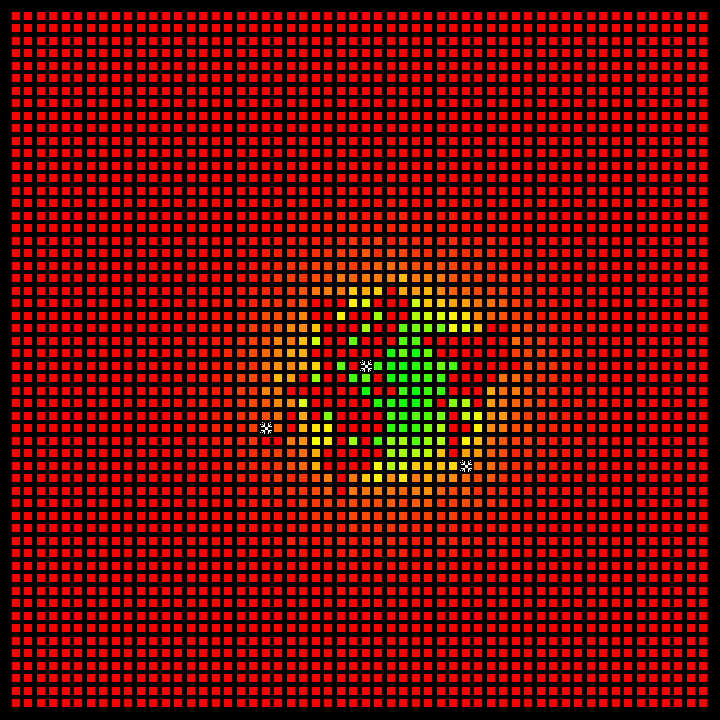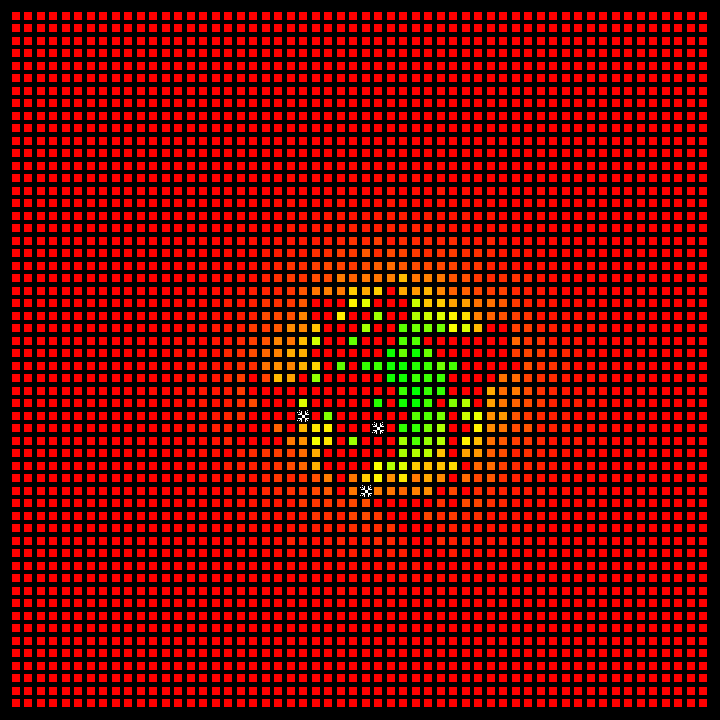
Fig 1: Representation of the environment in the Coverage Environment.
Quick Start
Warning
The DSSE project requires Python version 3.10.5 or higher.
To install GDAL (a requirement for using OpenDrift), you may need to install the following packages:
sudo apt install -y libgdal-dev gdal-binFor Windows, Microsoft Visual C++ 14.0 or greater is required for building.
Tip
After instancing the environment class, the beginning of simulation might take a while depending of your internet conection.
Install
pip install DSSE[coverage]
Use
Click me to view the code basic_coverage.py ⧉
from DSSE import CoverageDroneSwarmSearch
env = CoverageDroneSwarmSearch(
drone_amount=3,
render_mode="human",
disaster_position=(-24.04, -46.17), # (lat, long)
pre_render_time=10, # hours to simulate
)
opt = {
"drones_positions": [(0, 10), (10, 10), (20, 10)],
}
obs, info = env.reset(options=opt)
step = 0
while env.agents:
step += 1
actions = {agent: env.action_space(agent).sample() for agent in env.agents}
observations, rewards, terminations, truncations, infos = env.step(actions)
print(infos["drone0"])General Info
| Import | from DSSE import CoverageDroneSwarmSearch |
|---|---|
| Action Space | Discrete (9) |
| Action Values | [0, 1, 2, 3, 4, 5, 6, 7, 8] |
| Observation Space | {droneN: ((x, y), probability_matrix)} |
Action Space
| Value | Meaning |
|---|---|
| 0 | Move Left |
| 1 | Move Right |
| 2 | Move Up |
| 3 | Move Down |
| 4 | Diagonal Up Left |
| 5 | Diagonal Up Right |
| 6 | Diagonal Down Left |
| 7 | Diagonal Down Right |
| 8 | Do nothing |
tip
We incorporated 8 actions in this environment to enable the use of agents trained here in the Search Environment as well.
Inputs
| Inputs | Possible Values | Default Values |
|---|---|---|
render_mode | "ansi" or "human" | "ansi" |
render_grid | bool | True |
render_gradient | bool | True |
timestep_limit | int | 100 |
disaster_position | (float, float) | (-24.04, -46.17) |
drone_amount | int | 1 |
drone_speed | int | 10 |
drone_probability_of_detection | float | 1.0 |
pre_render_time | int | 10 |
prob_matrix_path | string | None |
particle_amount | int | 50,000 |
particle_radius | int | 800 |
num_particle_to_filter_as_noise | int | 1 |
start_time | datetime | None |
grid_cell_size | int | 130 |
render_mode:ansi: This mode presents no visualization and is intended to train the reinforcement learning algorithm.human: This mode presents a visualization of the drones actively searching the target, as well as the visualization of the person moving according to the input vector.
render_grid: If set to True along withrender_mode = "human", the visualization will be rendered with a grid. If set to False, there will be no grid when rendering.render_gradient: If set to True along withrender_mode = "human", the colors in the visualization will be interpolated according to the probability of the cell. Otherwise, the color of the cell will be solid according to the following values, considering the values of the matrix are normalized between 0 and 1:1 > value >= 0.75the cell will be green |0.75 > value >= 0.25the cell will be yellow |0.25 > valuethe cell will be red.timestep_limit: It's an integer that defines the length of an episode. This means that thetimestep_limitis essentially the number of steps that can be done without resetting or ending the environment.disaster_position: (float, float) parameter to specify the location of the event that let to PIW (Persons In Water), it receives atupleof floats, representing the latitue and longitute of said location. default value is (-24.04, -46.17), a point near the coast of Guaruja, Brazil.drone_amount: Specifies the number of drones to be used in the simulation. This integer parameter can be adjusted to simulate scenarios with different drone counts.drone_speed: An integer parameter that sets the drones' speed in the simulation, measured in meters per second(m/s). Adjust this value to simulate drones operating at various speeds.drone_probability_of_detection: This float parameter signifies the probability of a drone detecting an object of interest. Changing this value allows the user to simulate different detection probabilities.pre_render_time: This int parameter specifies the amount of time(hours)to pre-render the simulation before starting. Adjusting this value lets the user control the pre-rendering time of the simulation.prob_matrix_path: This string parameter allows the user to specify the path to file of a already simulated probability matrix. The file should be a.npyfile containing a probability matrix. If this parameter is not specified, the environment will generate a new probability matrix.particle_amount: This int parameter allows the user to customize the number of particles used in theLagrangian particle modelused to create the probability matrix.particle_radius: This int parameter allows the user tocustomizethe radius that the particles are randomly placed at the start of the Lagrangian particle model simulation.num_particle_to_filter_as_noise: This int parameter allows the user to modify the number of particles in each cell that are filtered to zero. (e.g. if the number of value is1, cells with only 1 particle in the end of simulation will be filtered to 0).start_time: This datetime parameter allows the user to specify thestart timeof the simulation. If not specified, the simulation will start at the current time.grid_cell_size: This int parameter allows the user to specify thesize of the gridcells in meters. The default value is 130 meters.
Built in Functions
env.reset:
The env.reset() reinitializes the environment to its initial state. To customize the starting conditions, such as drone positions, you can pass an options dictionary to the method. Here’s how to structure this dictionary and use the reset() method:
opt = {
"drones_positions": [(10, 5), (10, 10)],
}
observations, info = env.reset(options=opt)Parameters in the options Dictionary:
drones_positions: Specifies the initial[(x, y), (x, y), ...]coordinates for each drone. Ensure this list contains an entry for each drone in the environment.
Default Behavior:
Without any arguments, env.reset() will place drones sequentially from left to right in adjacent cells. When there are no more available cells in a row, it moves to the next row and continues from left to right.
Return Values:
The method returns an observations dictionary containing observations for all drones, which provides insights into the environment's state immediately after the reset. The info dictionary contains additional information about the environment.
env.step:
The env.step() method defines the drone's next movement. It requires a dictionary input where each key is a drone's name and its corresponding value is the action to be taken. For instance, in an environment initialized with 10 drones, the method call would look like this:
env.step({
'drone0': 2, 'drone1': 3, 'drone2': 2, 'drone3': 5, 'drone4': 1,
'drone5': 0, 'drone6': 2, 'drone7': 5, 'drone8': 0, 'drone9': 1
})Warning
Every drone listed in the dictionary must have an associated action. If any drone is omitted or if an action is not specified for a drone, the method will raise an error.
The method returns a tuple containing the following elements in order:
Observation: The new state of the environment after the step.Reward: The immediate reward obtained after the action.Termination: Indicates whether the episode has ended (e.g., find all castway, limit exceeded).Truncation: Indicates whether the episode was truncated (e.g., through a timeout).Info: A dictionary containing auxiliary diagnostic information.
Probability Matrix
The probability matrix is created using a Lagrangian particle simulation facilitated by the Opendrift library. In this process, particles are released at a disaster site and drift with water currents. Those reaching the coast are removed from the simulation. The matrix is constructed by recording the number of particles that reach each grid cell, thus encapsulating the data accumulated throughout the simulation. The final locations of these particles are documented to form the matrix.
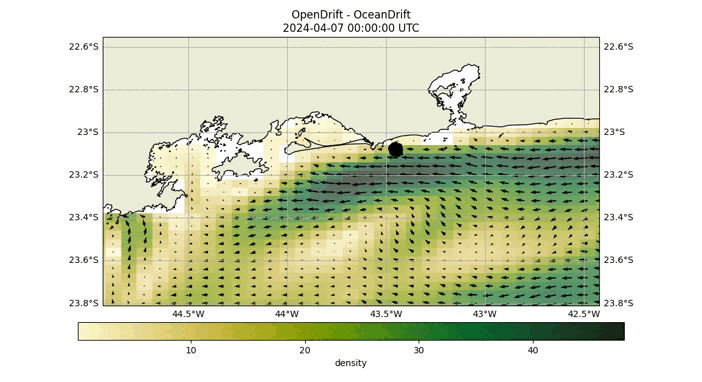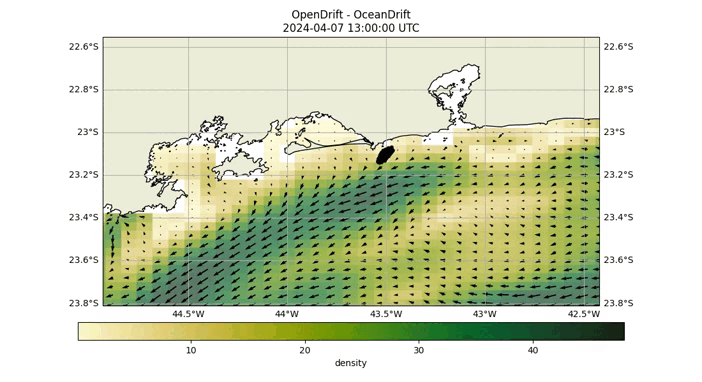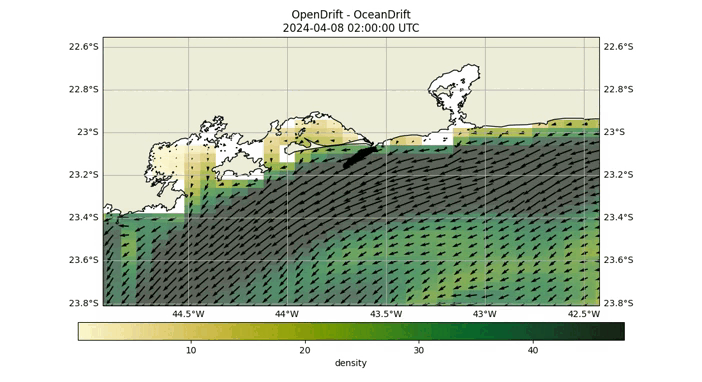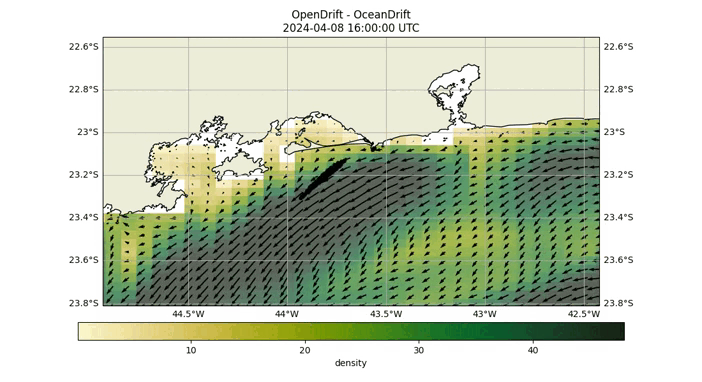
Fig 2: Opendrift simulation over 40 hours, starting at coordinates (-24.04, -46.17).
As demonstrated in the above GIF, after conducting the Opendrift simulation, we ascertain the final positions of the particles and proceed to construct the probability matrix. This matrix is visually represented by the blue particles in the image below.
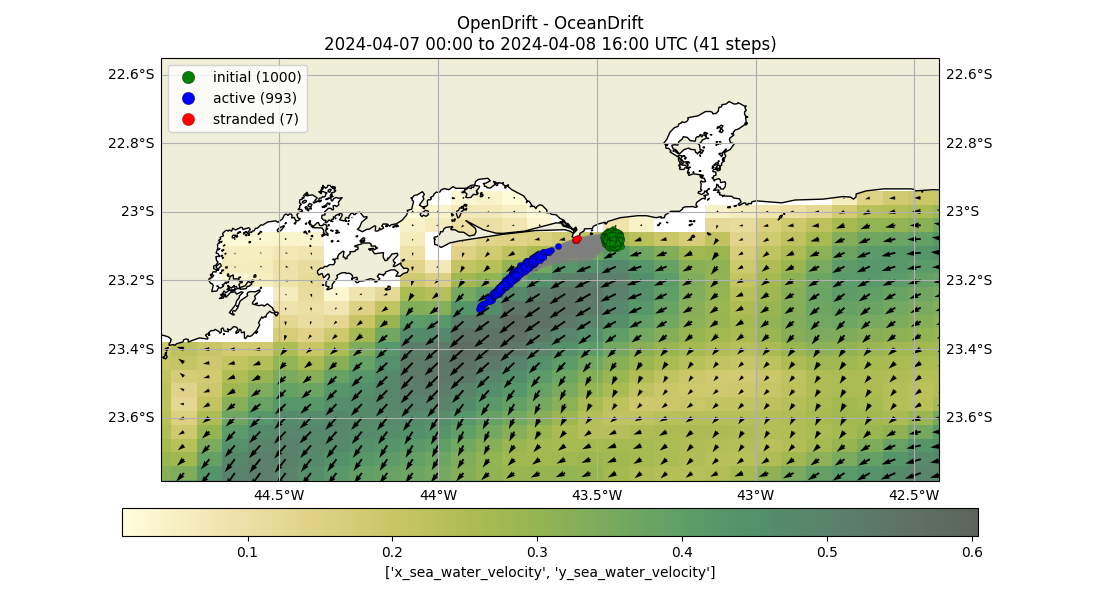
Fig 3: Final positions of particles from an Opendrift simulation.
Following the collection of particle data, we generate the probability matrix. Each cell in this matrix represents the likelihood of discovering a person at that particular location, as depicted in the subsequent image.
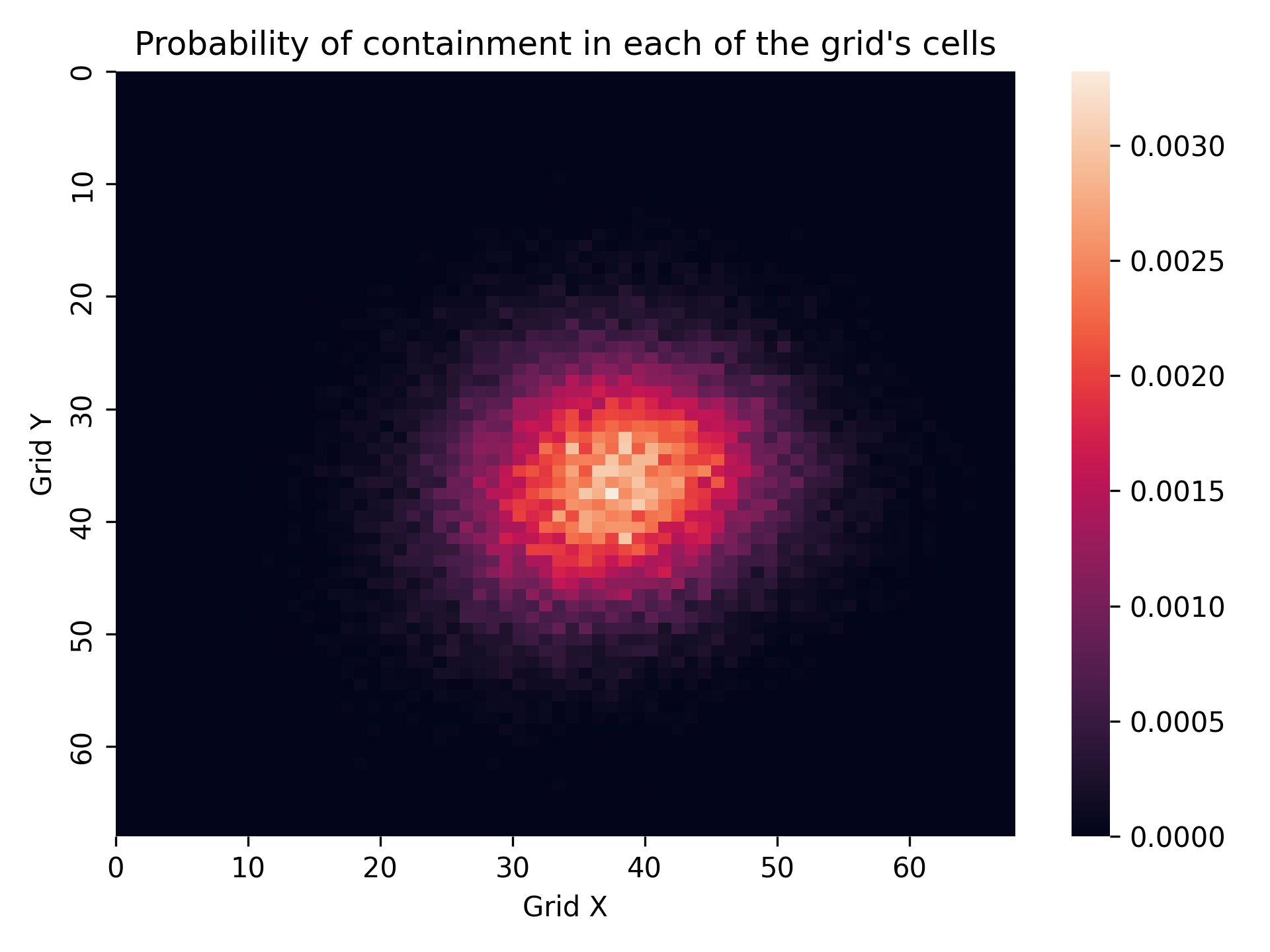
Fig 4: Final probability matrix.
Probability Matrix: The probability indicated in each cell reflects the likelihood of finding a person in that specific location.
Observation
The observation is a dictionary with all the drones as keys, identified by names such as drone0, drone1, etc. Each key is associated with a tuple that contains the drone's current position and its perception of the environment, represented as a probability matrix.
- Tuple Structure:
((x_position, y_position), probability_matrix)x_position,y_position: The current coordinates of the drone on the grid.probability_matrix: A matrix representing the drone's view of the probability distribution of the target's location across the grid.
An output example can be seen below.
{
'drone0':
((5, 5), array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
),
'drone1':
((25, 5), array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
),
'drone2':
((45, 5), array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
),
.................................
'droneN':
((33, 45), array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
),
}Reward
The reward returns a dictionary with the drones names as keys and their respectful rewards as values. For example {'drone0': 1, 'drone1': 89.0, 'drone2': 1}
The rewards values goes as follows:
Default Action: Every action receives a baseline reward of-0.2.Searching a Cell: The reward for searching a cell is proportional to the probability p of the cell being searched, denoted as1 + (1 - Ts / Ts_limit) * p * n_cells, beingn_cellsthe number of cells with probability greater than 0, Ts being the terminal timestep and Ts_limit the limit of timesteps.Complete the searching: If all cells are searched, the reward isn_cells + n_cells * (1 - Ts / Ts_limit).
Termination & Truncation
The termination and truncation variables return a dictionary with all drones as keys and boolean as values. By default, these values are set to False and will switch to True under any of the following conditions:
Time Limit Exceeded: If the simulation's timestep exceeds thetimestep_limit.Done searching all cells: If the agents have searched all cells with probability > 0.
For example, the dictionary might look like this:
{'drone0': False, 'drone1': False, 'drone2': False}Info
The Info is structured as a dictionary of dictionaries, where each drone, such as drone0, serves as a key. The associated value is another dictionary containing several key metrics:
is_completed: a boolean indicating whether the drone has searched all grid cells. It starts as False and changes to True once the drone has completed its search.coverage_rate: the percentage of the grid that has been covered by the drone.repeated_coverage: the percentage of the grid that has been covered more than once, indicating overlap in search areas.accumulated_pos: The accumulated Probability of Sucess (POS) of the SAR mission, this serves as a way to quantify the chance of finding all SAR targets within a mission.
The info section serves as an indicator of the progress of the search operation.
For example, here is how the dictionary appears before any drone has completed its search:
{'drone0': {'is_completed': False, 'coverage_rate': 0.5693877551020409, 'repeated_coverage': 0.0010204081632653062, 'acumulated_pos': 0}}After a drone successfully locates the person, the dictionary updates to reflect this:
{'drone0': {'is_completed': True, 'coverage_rate': 100, 'repeated_coverage': 2.912397984939490308, 'acumulated_pos': 1.0}}This setup allows users to continuously monitor and assess the effectiveness of the search operation during the simulation.
env.get_agents:
The env.get_agents() method will return a list of all the possible agents (drones) currently initialized in the simulation, you can use it to confirm that all the drones exist in the environment. For example, in an environment configured with 10 drones, the method would return:
['drone0', 'drone1', 'drone2', 'drone3', 'drone4', 'drone5', 'drone6', 'drone7', 'drone8', 'drone9']env.save_matrix:
The env.save_matrix() method enables saving the probability matrix as a .npy file. To use this method, you must provide a string parameter that specifies the file path where the matrix should be saved. For example:
env.save_matrix("path/to/save/matrix.npy")After saving, you can load this matrix in a newly created environment using the prob_matrix_path parameter:
env = CoverageDroneSwarmSearch(
drone_amount=3,
render_mode="human",
disaster_position=(-24.04, -46.17), # (lat, long)
pre_render_time=10, # hours to simulate
prob_matrix_path="path/to/save/matrix.npy"
)Warning
Ensure that the disaster_position and pre_render_time parameters are the same as those used to generate the matrix to maintain consistency in the simulation conditions.
Tip
The env.save_matrix() method is not only convenient for saving the probability matrix post-simulation but also essential for reusing it in subsequent simulations without needing to regenerate it. It facilitates varying simulation parameters, such as the number of drones, their speed, or timestep, for different experimental setups.
env.close:
env.close() will simply close the render window. Not a necessary function but may be used.
Stay Updated
We appreciate your patience and interest in our work. If you have any questions or need immediate assistance regarding our Coverage Environment, please do not hesitate to contact us via our GitHub Issues page.
License
This documentation is licensed under the terms of the MIT License. See the LICENSE file for more details.