

Drone Swarm Search: Algorithms
About
Welcome to our Algorithms repository! These algorithms are specifically tailored for the environments available in DSSE, aimed at optimizing drone swarm coordination and search efficiency.
Explore a diverse range of implementations that leverage the latest advancements in machine learning to solve complex coordination tasks in dynamic and unpredictable environments. Our repository offers state-of-the-art solutions designed to enhance the performance and adaptability of autonomous drone swarms, making them more efficient and effective in various search and rescue missions.
| Search Environment |
|---|
 |
| Coverage Environment |
|---|
 |
Algorithms Implemented
In this project, we have utilized the RLlib library, a library designed for reinforcement learning (RL), to develop our algorithms. Our implementations are based on a Multi-Input Convolutional Neural Network (CNN) architecture, adeptly handling the complex dynamics of the environments we are exploring.
Multi-Input CNN Architecture
The neural network architecture employed here is specifically designed to process multiple types of input data simultaneously, reflecting the comprehensive state of the environment:
Probability Matrix: This input encapsulates a matrix of probabilities, providing a possible position for the target within the environment.Agent Positions: The second input consists of the spatial positions of agents within the environment. This allows the network to integrate spatial awareness with probabilistic insights, offering a nuanced understanding of the environment.
By combining these data, our CNN can effectively interpret and react to the full scope of environmental observations.
Proximal Policy Optimization (PPO): An Overview
Proximal Policy Optimization (PPO) is a widely used algorithm in the field of reinforcement learning (RL), known for its effectiveness and relative simplicity. It belongs to a class of algorithms called policy gradient methods, which optimize the policy directly. PPO aims to improve training stability and efficiency by addressing the problem of large policy updates, which can destabilize learning in RL.
Centralized vs. Decentralized Implementations
PPO can be implemented in two distinct ways: centralized and decentralized.
Centralized PPO:- In a centralized setup, a single neural network is used for
all agentsin the environment. This network learns a policy that collectively governs the actions ofall agents. The primary advantage of this approach is that it allows for a unified update mechanism whereall agentscontribute to and benefit from a single learning model, promoting consistency in the learned policy. - Centralized PPO is particularly useful in scenarios where agents’ actions are interdependent, and the state and reward information from all agents can be aggregated to make more informed policy updates.
- In a centralized setup, a single neural network is used for
Decentralized PPO:- Conversely, decentralized PPO employs a separate neural network for
each agent. Each network learns an individual policy based on the agent's own experiences. This approach is advantageous in environments where agents have distinct roles or when their observations and objectives differ significantly. - Decentralized PPO supports greater customization of learning and adaptation for
each agent, potentially leading to more robust performance in diverse or non-uniform settings.
- Conversely, decentralized PPO employs a separate neural network for
Core Mechanism
Regardless of the implementation style, the core mechanism of PPO revolves around optimizing the policy in a way that avoids too large updates. PPO introduces a clipped surrogate objective function, which helps in managing the size of policy updates. This clipping mechanism limits the ratio of new policy probabilities to old policy probabilities, ensuring that the updates are neither too small (leading to slow learning) nor too large (causing instability).
Deep Q-Network (DQN): Implementation Overview
The Deep Q-Network (DQN) algorithm is a foundational approach in the field of reinforcement learning, particularly known for combining Q-learning with deep neural networks. DQN extends the capabilities of traditional Q-learning by using deep neural networks to approximate the Q-value function, which represents the expected rewards for taking an action in a given state.
Network Architecture
Similar to Proximal Policy Optimization (PPO), DQN can leverage advanced neural network architectures. However, while the core architectural framework might be shared with PPO, the specific implementations and output layers are tailored to meet the distinct requirements of each algorithm:
Shared Architectural Features:
- Input Layer: Both DQN and PPO typically use a similar input layer that processes the state representations from the environment. This could be raw pixel data from a video game or a set of numerical features describing the state in a more abstract environment.
- Hidden Layers: The hidden layers are generally composed of multiple dense or convolutional layers (depending on the input type). These layers are responsible for extracting features and learning the complex patterns necessary for decision-making.
Distinct Output Specifications:
- DQN Output: In DQN, the output layer is specifically designed to provide a separate output for each possible action in the environment. Each output corresponds to the estimated Q-value for taking that action given the current state. This is crucial for the DQN's decision-making process, as the action with the highest Q-value is typically selected.
- PPO Output: On the other hand, PPO's output layer generally includes probabilities associated with each action (for policy output) and a value estimate (for value function output), reflecting the dual needs of policy gradient methods.
Key Implementation Details
The adaptation from a general neural network architecture, like that used in PPO, to one suitable for DQN involves focusing on the unique characteristics of Q-learning:
- Loss Function: DQN uses a loss function that minimizes the difference between the currently estimated Q-values and the target Q-values, which are periodically updated from a target network to provide stable learning targets.
- Exploration vs. Exploitation: DQN implements strategies such as ε-greedy to balance exploration (choosing random actions) and exploitation (choosing actions based on the learned Q-values), crucial for effective learning.
- Experience Replay: DQN typically utilizes an experience replay mechanism that stores transitions and samples from them randomly to break the correlation between consecutive learning samples, thereby stabilizing the training process.
Conclusion
While DQN and PPO may share underlying neural network architectures, the specific adaptations and configurations in the output layer and training protocol distinguish DQN and allow it to effectively learn optimal policies in environments where the agent must evaluate discrete actions. This flexibility to adapt a core architecture to different algorithmic needs underscores the modularity and power of modern neural network approaches in reinforcement learning.
Hypotheses
In our examination of the DSSE, we propose 5 key hypotheses to guide our exploration and analysis. These hypotheses are structured to test the effectiveness of various reinforcement learning strategies and configurations within two distinct environments: the Search Environment and the Coverage Environment.
Search Environment Hypotheses
- Effectiveness of RL vs. Greedy Algorithms:
Hypothesis: Reinforcement Learning (RL) algorithms can be moreeffectivethan traditional greedy algorithms?Rationale: RL algorithms potentially adapt better to complex, dynamic environments by learning optimal policies over time, unlike greedy algorithms that make decisions based solely on current available information.
INFO
The Greedy algorithm is a simple, heuristic-based approach to go the highest probability cell in the probability matrix and search for the target. It is a baseline algorithm to compare the performance of RL algorithms.
Centralized vs. Decentralized PPO:
Hypothesis: decentralized PPO canoutperformCentralized PPO?Rationale: Decentralized PPO allows each agent to learn and adapt based on its individual experiences and unique view of the environment. This independence can lead to more flexible and tailored decision-making processes, especially in scenarios where agents face distinct challenges or operate in different parts of the environment. This approach may prove advantageous in managing localized complexities and dynamics, potentially enhancing overall system performance by optimizing local decisions.
Impact of Communicating Target Trajectory:
Hypothesis: Communicating the trajectory of the target to the agents canimprovethe performance of the algorithms.Rationale: Providing agents with trajectory information can enhance their predictive capabilities and strategic positioning, leading to quicker and more efficient target localization.
Multi-Target Handling:
Hypothesis: RL algorithms will effectively manage scenarios involving multiple targets, assessing how agentstrategies adaptwhen faced with increased task complexity.Rationale: Understanding the adaptability of RL algorithms in multi-target scenarios will help in evaluating their scalability and robustness in complex environments.
Coverage Environment Hypothesis
- Efficiency and Prioritization in Coverage:
Hypothesis: Agents can cover the environment in the least time possible and prioritize areas with the highest probability of containing relevant targets or events.Rationale: Effective coverage strategies should not only aim for speed but also for strategic prioritization based on probabilistic assessments, maximizing the efficiency of the search and surveillance operations.
These hypotheses aim to systematically explore the capabilities and limitations of reinforcement learning in diverse and challenging scenarios within the DSSE framework, providing insights into the potential and practical applications of these technologies in real-world situations.
Results
Hypothesis 1: Effectiveness of RL vs. Greedy Algorithms
Result: This comparison was conducted with four agents and one target in the search environment, with two tests featuring dispersion increments of0.05and0.1. Both the PPO and DQN algorithms were implemented in their centralized versions. As depicted inFigures 1 and 2, the PPO algorithm successfully found a good policy, whereas the DQN algorithm struggled, as indicated inFigure 3below. Furthermore, comparisons inTable 1 and 2and additional data show that the PPO algorithm consistently outperformed the Greedy algorithm.
WARNING
Because the DQN not working as expected, we have not included the DQN results in the tables for all hypotheses.
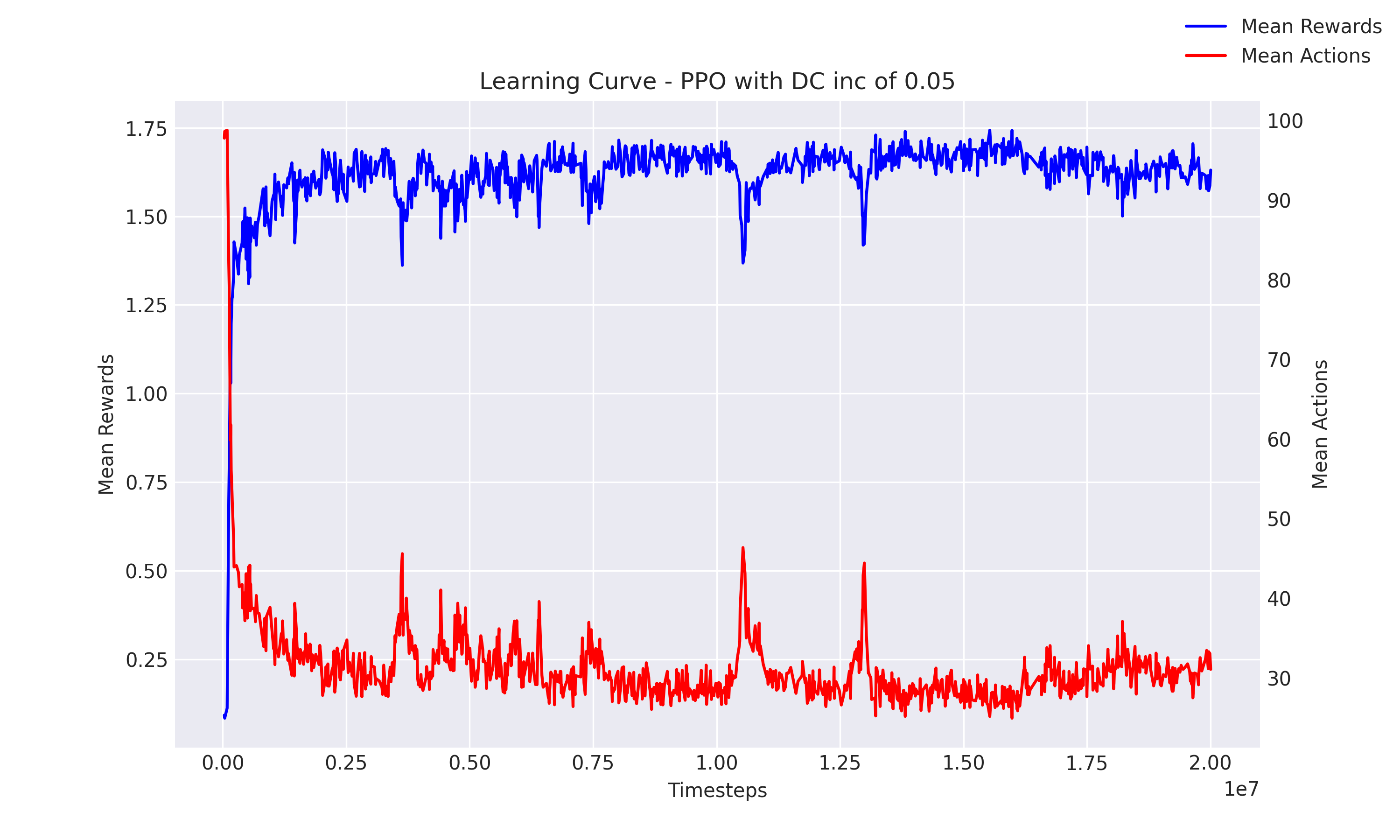
Figure 1: PPO Search Performance with Dispersion 0.05
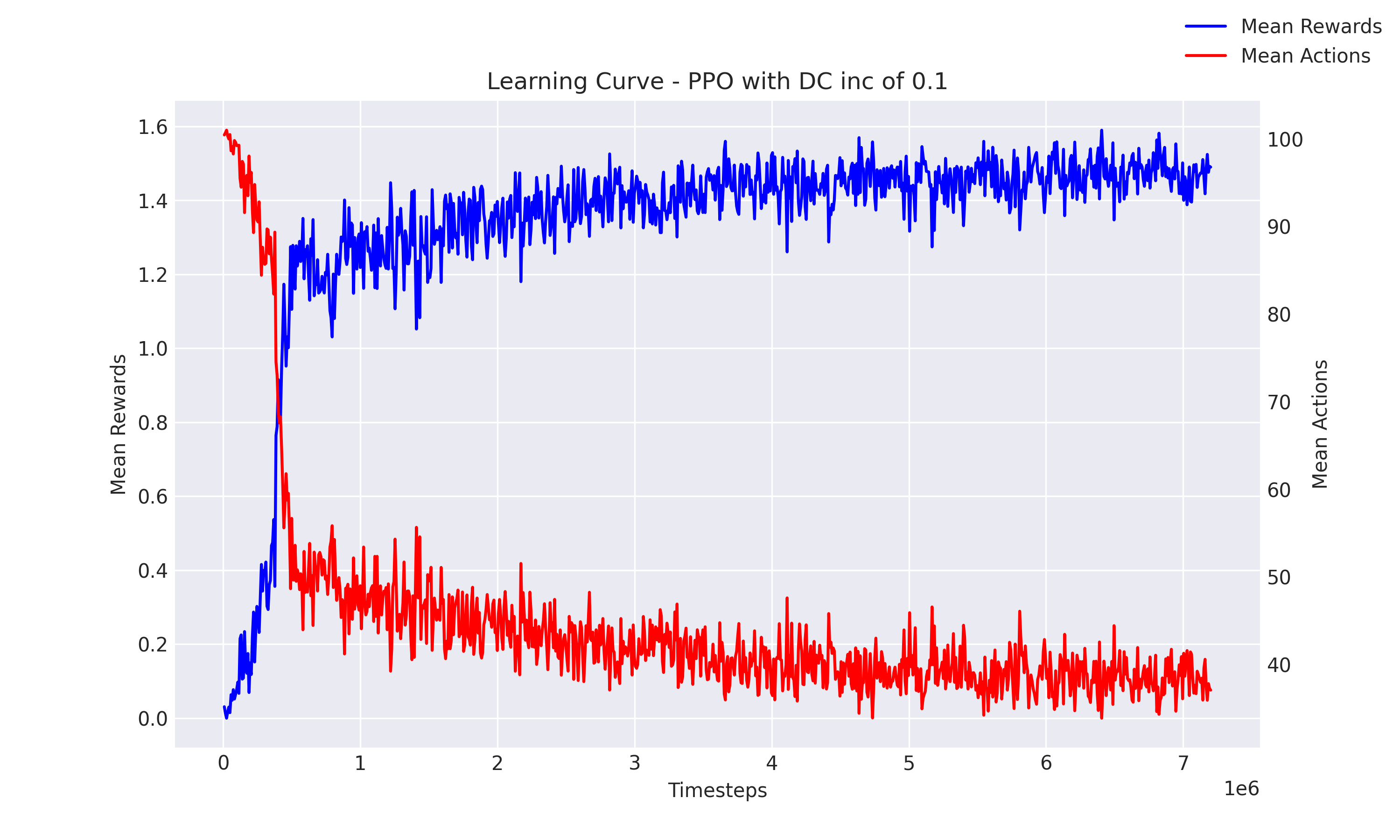
Figure 2: PPO Search Performance with Dispersion 0.1
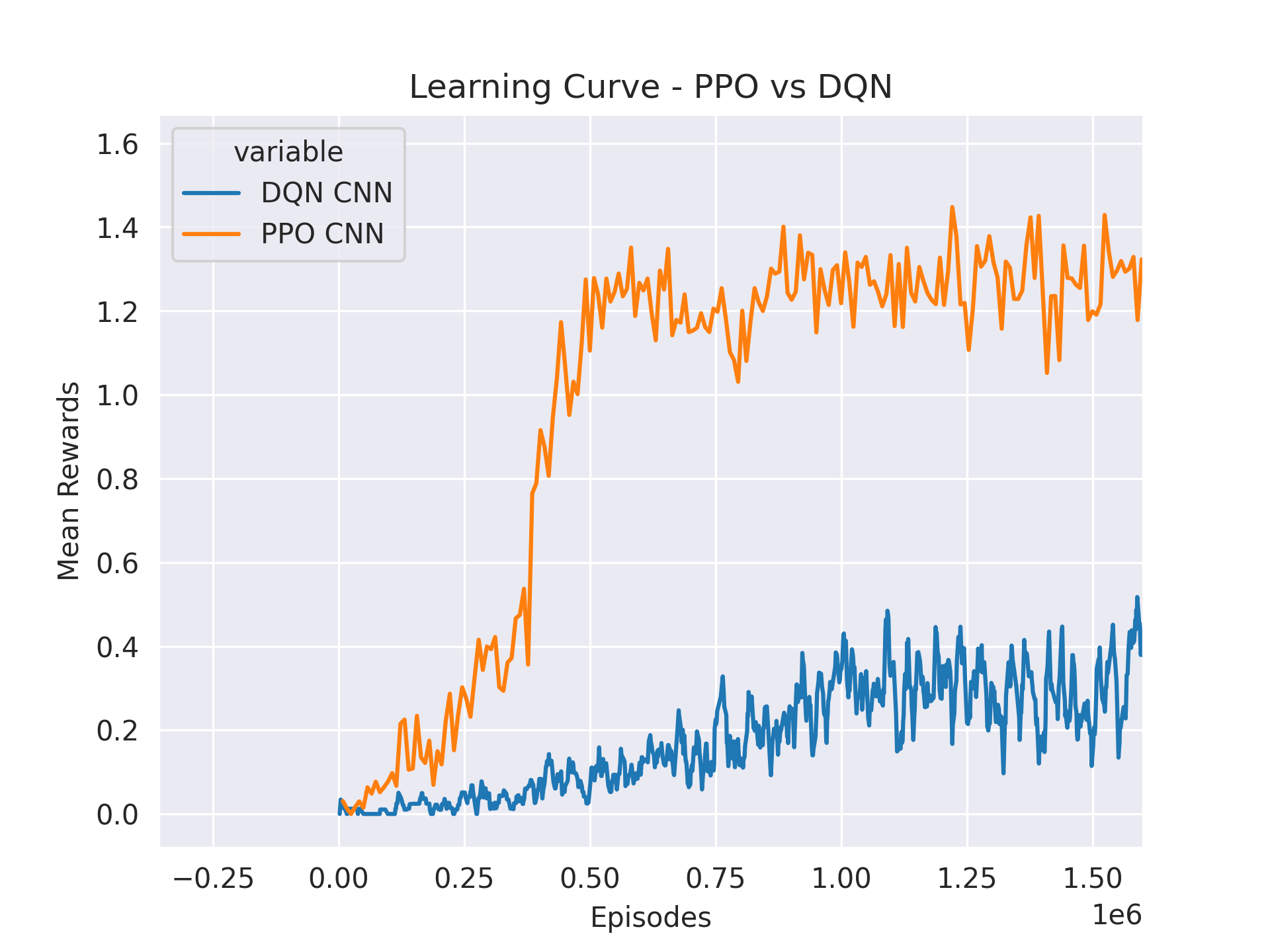
Figure 3: DQN vs PPO Performance Comparison
Table 1: Performance Metrics Comparison Between PPO and Greedy Algorithms with 0.05 dispersion
| Metric | PPO | Greedy Search |
|---|---|---|
| Success Rate (%) | 83.0 | 50.18 |
| Average Number of Actions | 35.91 | 65.07 |
| Median Number of Actions | 22.0 | 94 |
| Average Reward | 1.48 | 0.86 |
Table 2: Performance Metrics Comparison Between PPO and Greedy Algorithms with 0.1 dispersion
| Metric | PPO | Greedy Search |
|---|---|---|
| Success Rate (%) | 75.44 | 35.84 |
| Average Number of Actions | 42.47 | 77.48 |
| Median Number of Actions | 23 | 100 |
| Average Reward | 1.34 | 0.59 |

Gif 1: Train PPO performance

Gif 2: Greedy algorithm performance
Conclusion
The results indicate that RL algorithms, particularly PPO, adapted more dynamically to changing conditions, demonstrating a higher utility in complex environments compared to the more static Greedy algorithm. The performance metrics highlight the efficiency and effectiveness of PPO in reducing the number of actions needed and increasing the success rate, thereby affirming the hypothesis that RL algorithms can be more effective than Greedy algorithms in the search environment.
Hypothesis 2: Centralized vs. Decentralized PPO
Result: In our evaluation, we analyzed the performance of decentralized versus centralized PPO across various settings. The decentralized PPO was observed to be slower in terms of convergence speed but was able to achieve similar levels of performance as the centralized PPO, as shown inFigure 4. Further tests also revealed that the speed of convergence and overall performance of PPO architectures do not consistently favor one form over the other but depend heavily on specific variables such as hyperparameters and environmental characteristics.
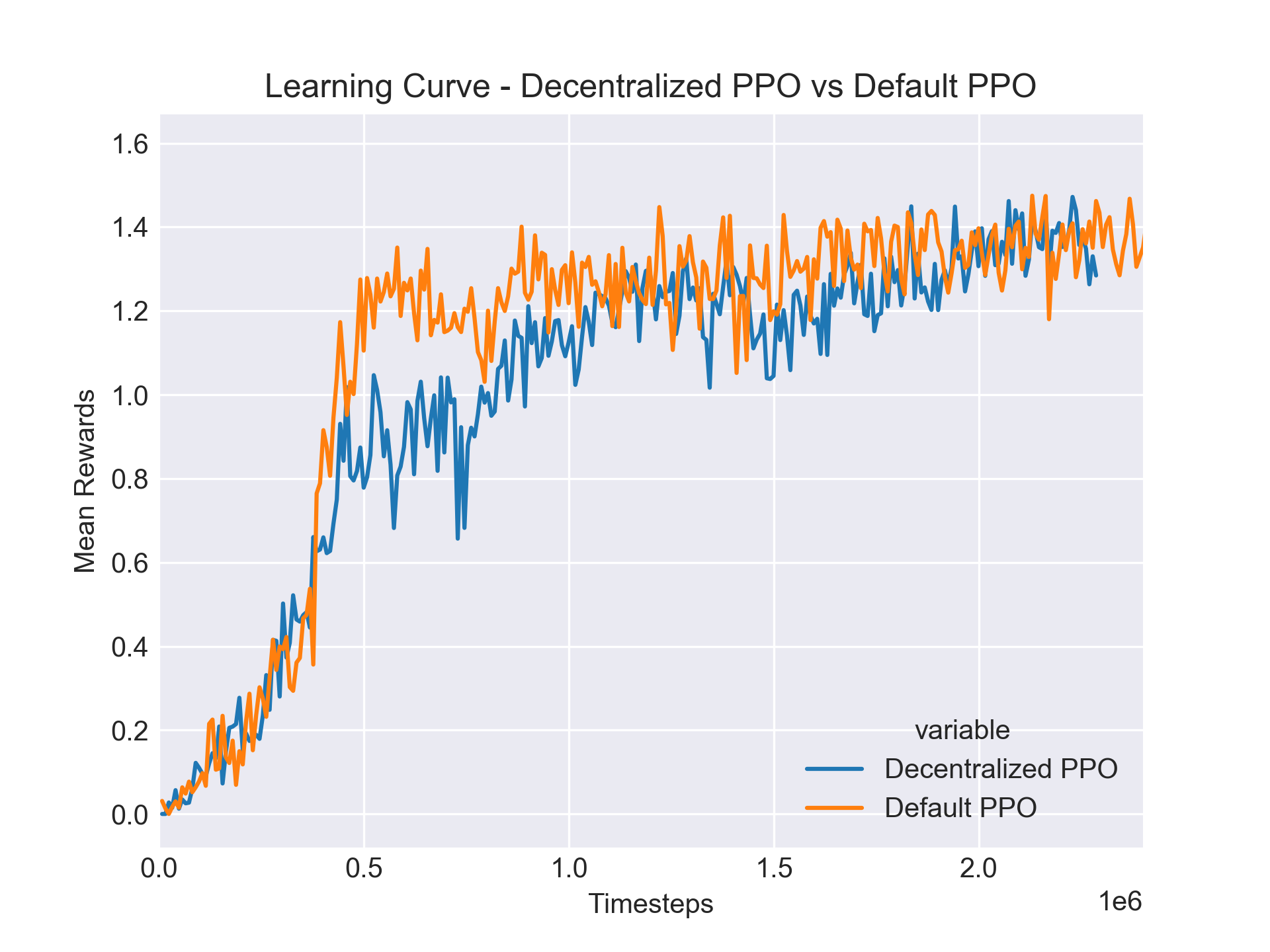
Figure 4: Centralized vs Decentralized PPO Convergence
Discussion: The graph clearly illustrates that while the decentralized approach may take longer to converge, it ultimately reaches a performance parity with the centralized approach. This finding is crucial as it suggests that the decision between using a centralized or decentralized approach should be informed by the specific dynamics and demands of the environment rather than a predefined preference for one model.Further Analysis: Our extensive testing highlighted the significant impact of various factors on the performance of decentralized and centralized PPO. These factors include but are not limited to the agents' ability to adapt to their individual parts of the environment, the complexity of the tasks, and the inter-agent dependencies.
Conclusion
The analysis confirms that both decentralized and centralized PPO have their merits, and their effectiveness can vary based on the context and setup of the deployment. This nuanced understanding helps in selecting the right PPO architecture tailored to specific operational needs and conditions.
Hypothesis 3: Impact of Communicating Target Trajectory
Result: Our experiments explored the effect of including target trajectory information in the training of PPO algorithms. We compared three different setups: standard PPO, PPO with trajectory information incorporated into the probability matrix, and PPO enhanced with an LSTM to handle sequential data. The results, illustrated inFigure 5and summarized inTable 3, indicate that incorporating trajectory information did not enhance performance. This lack of improvement suggests that the standard environmental observations provided may already be sufficient for the algorithms to learn effectively. Alternatively, the minimal number of agents used in the tests, four, might have limited the potential benefits of enhanced communication, suggesting that more extensive tests with additional agents might yield different results.
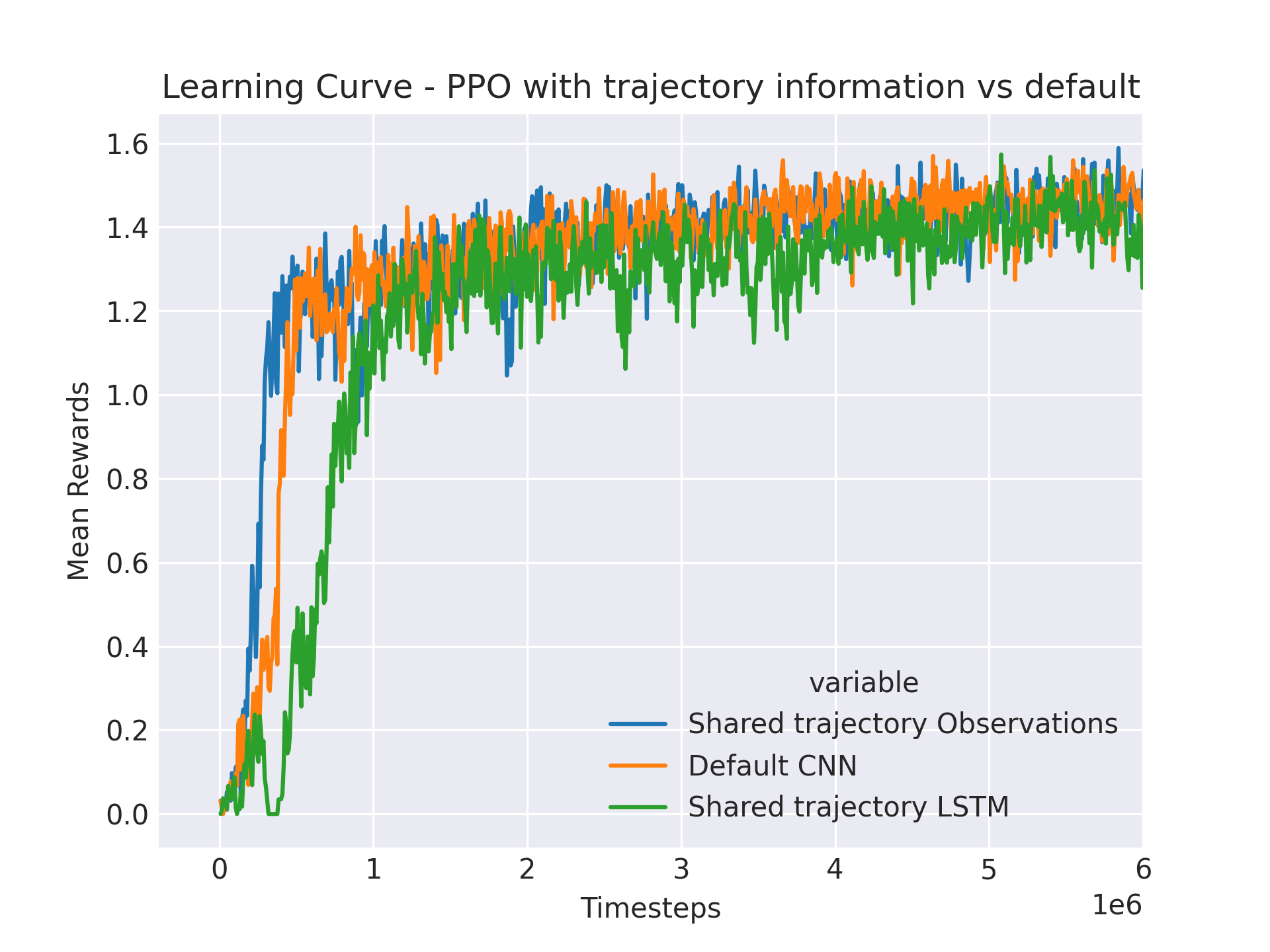
Figure 5: Comparison of PPO Variants with and without Trajectory Information
Table 3: Performance Metrics for PPO Variants
| Algorithm | Standard PPO | PPO with Trajectory Matrix | PPO with LSTM |
|---|---|---|---|
| Success Rate (%) | 75.44 | 75.98 | 76.46 |
| Average Number of Actions | 42.47 | 41.99 | 41.57 |
| Median Number of Actions | 23 | 23 | 23 |
| Average Reward | 1.34 | 1.35 | 1.36 |
Discussion: The graph and table clearly show that the addition of trajectory information does not impact the performance metrics, as all variants of PPO reported essentially identical outcomes. This observation raises important questions about the redundancy of additional information when the existing data is already comprehensive and effectively utilized by the algorithm.Further Analysis: Considering the potential for the communication of trajectory information to be more impactful in larger, more complex agent configurations, further experiments with an increased number of agents might elucidate the conditions under which enhanced communication could improve performance. Such tests could help determine whether the current findings are generally applicable or if they are specific to scenarios with limited agent numbers.
Conclusion
The current results suggest that for environments where standard observations are rich and detailed, the addition of explicit trajectory communication may not provide additional benefits. Future research should focus on varying the number of agents and exploring different environmental complexities to fully understand the potential and limitations of incorporating trajectory information.
Hypothesis 4: Multi-Target Handling by RL Algorithms
Result: We conducted experiments to evaluate the performance of the PPO algorithm in scenarios with multiple targets, specifically testing with four targets at a dispersion level of 0.1. The results, displayed inFigure 6and summarized inTable 4, suggest that while the PPO algorithm is capable of locating castaways, it tends to adhere to a suboptimal policy similar to the one used when searching for a single castaway. This indicates that although the algorithm successfully learns to find multiple targets, it does not optimize its strategy to handle multiple targets more efficiently than it handles a single target.
Figure 6: PPO Performance in Multi-Target Search
Table 4: Evaluation of PPO Results for Four Castaways
| Metric | PPO |
|---|---|
| Found all castaways (% of tests) | 21.54 |
| Average number of castaways found | 2.3 |
| Average number of actions | 86.81 |
Discussion: The graph and table data reveal that PPO, despite being able to identify multiple targets, does not show significant strategic adaptation when the number of targets increases. This behavior results in performance that, while effective to a degree, remains locked in strategies that do not fully exploit the possibilities of optimizing actions across multiple targets. The relatively low percentage of tests in which all targets were found and the average number of actions suggest that the algorithm settles into a suboptimal approach.Further Analysis: It would be insightful to compare these results with scenarios involving fewer targets to assess how the increase in target number impacts the optimization strategies of PPO. Additionally, experimenting with different algorithm configurations or enhanced learning techniques such as incorporating advanced heuristics or meta-learning could potentially lead to improved outcomes.

Gif 3: Train PPO performance with 4 targets
Conclusion
The findings indicate that while PPO can handle the addition of multiple targets up to a certain extent, its strategy does not scale proportionally with an increase in complexity posed by multiple simultaneous objectives. This highlights the need for further development and adjustment of the algorithm or its training process to better accommodate scenarios with multiple targets, ensuring more efficient and effective search strategies. Future research should also investigate the integration of more dynamic and flexible learning mechanisms to enable the algorithm to adjust its policy based on the complexity and demands of the environment.
Hypothesis 5: Efficiency and Prioritization in Coverage
Result: The experiments conducted under this hypothesis aimed to evaluate the agent's ability to efficiently cover the environment while prioritizing areas of higher probability. The results, depicted inFigure 7and demonstrated inGif 4, confirm that the agent has successfully learned to search all cells with a notable preference for cells with higher probabilities. The graph indicates effective coverage of all cells, and the gif visually supports the agent’s behavior towards higher probability cells. On average, the agents complete the task in 34 steps, which is significant considering the environment consists of 58 cells. This efficiency translates to achieving coverage in 58.6% of the total possible steps, suggesting an effective parallelization of tasks, especially given that two agents were used in these experiments.
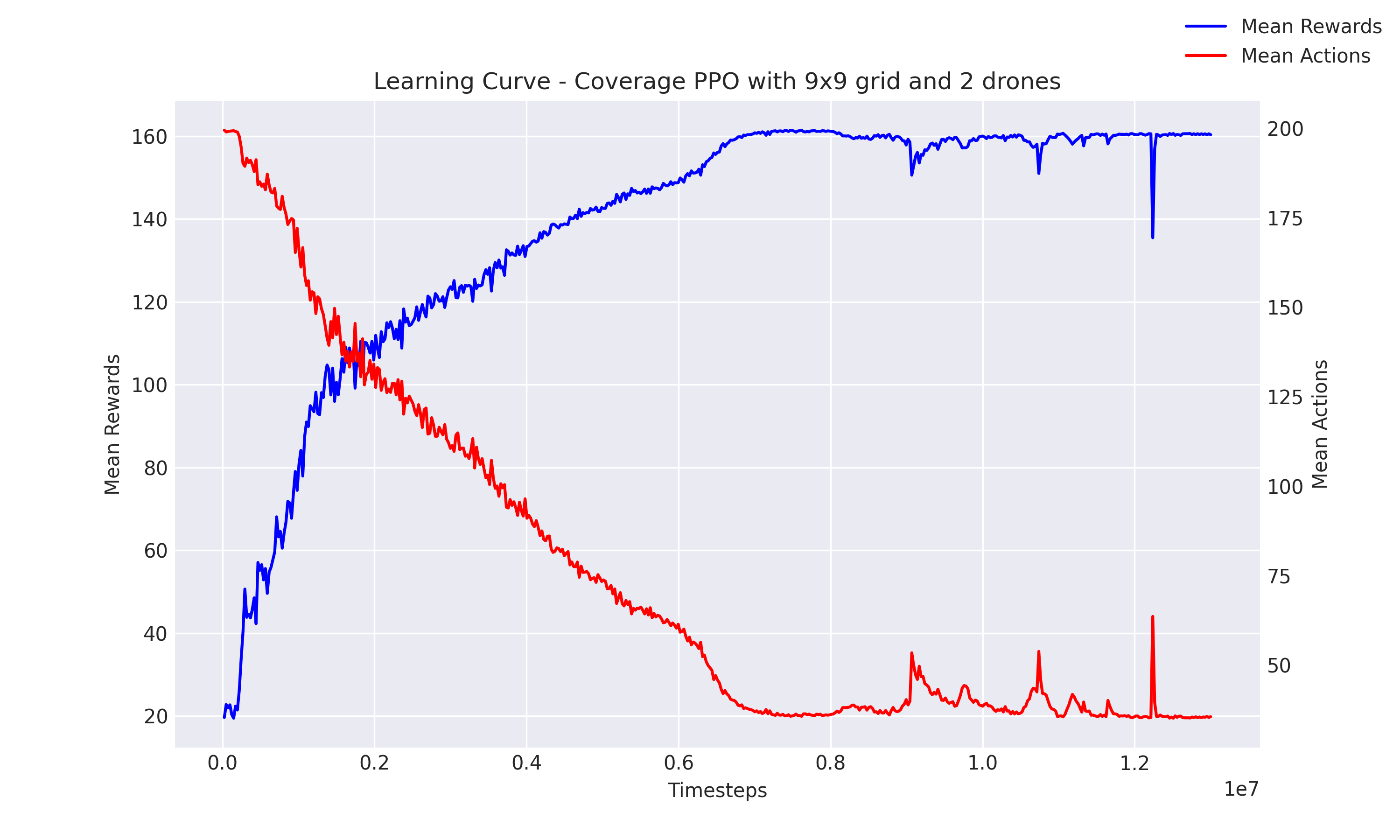
Figure 7: Learning Curve Showing Coverage Efficiency

Gif 4: Agent Behavior Prioritizing High Probability Cells
Analysis: The graph and gif together illustrate not only the agents' capability to comprehensively cover the search area but also their strategic optimization to prioritize more probable areas. This strategic behavior is particularly notable because the problem they are solving is inherently complex. This coverage problem is provably anNP-completeproblem, with the complexity escalating to n factorial (n!), where n represents the number of cells. The ability of the agents to nearly halve the necessary steps for complete coverage with two agents indicates a high level of optimization and problem-solving efficiency.
Conclusion
These findings highlight the advanced capabilities of the agents in not only understanding and adapting to the task requirements but also in optimizing their path to focus on areas of highest impact. The performance of the agents in this NP-complete environment suggests potential for applying similar strategies to other complex and computationally intensive tasks, where strategic prioritization and efficiency are critical.
Test Configurations
This appendix provides detailed configurations and hyperparameters used during the testing of different algorithms and environments in our experiments.
Hyperparameters for PPO
The following table outlines the hyperparameters used for the Proximal Policy Optimization (PPO) algorithm during our experiments:
Table A1: Hyperparameters for PPO
| Parameter | Value | Description |
|---|---|---|
| B | 8192 | Training batch size |
| Lr | 10^-5 | Learning rate |
| 𝛾 | 0.9999999 | Discount factor |
| M | 300 | Stochastic Gradient Descent (SGD) minibatch |
| K | 10 | Number of SGD iterations |
Hyperparameters for DQN
The following table outlines the hyperparameters used for the Deep Q-Network (DQN) algorithm during our experiments:
Table A2: Hyperparameters for DQN
| Parameter | Value | Description |
|---|---|---|
| B | 8192 | Training batch size |
| Lr | 10^-5 | Learning rate |
| 𝛾 | 0.9999999 | Discount factor |
| U | 500 | Update target network every U steps |
| 𝜀0 | 1 | Initial epsilon for 𝜀-greedy |
| 𝜀f | 0.1 | Final epsilon for 𝜀-greedy |
| T | 400000 | T timesteps for epsilon to decay from 𝜀0 to 𝜀f |
Environment Settings for Search Tests
The following table provides the settings for the search environment used in the tests:
Table A3: Environment Settings for Search Tests
| Parameter | Value |
|---|---|
| Dispersion increment | 0.1 (0.05 H1) |
| Number of Persons in Water (PIW) | 1 (4 H5) |
| Grid size | 40x40 |
| Number of drones | 4 |
| Maximum number of timesteps per simulation | 100 |
Environment Settings for Coverage Tests
The following table provides the settings for the coverage environment used in the tests:
Table A4: Environment Settings for Coverage Tests
| Parameter | Value |
|---|---|
| Hours of particle simulation | 2 |
| Wreck position (near Guarujá, ocean) | -24.04 lat, -46.17 long |
| Grid size | 9x9 |
| Number of drones | 4 |
| Maximum number of timesteps per simulation | 200 |
How to Run
To run the experiments, you will need to navigate to the algorithms directory and execute scripts located in the src/ folder. Below is a brief description of the relevant scripts and the instructions on how to run them for each hypothesis testing.
src/
├── greedy_heuristic.py
├── min_matrix.npy
├── recorder.py
├── test_ppo_cnn.py
├── test_trained_cnn_lstm.py
├── test_trained_cov.py
├── test_trained_cov_mlp.py
├── test_trained_search.py
├── train_descentralized_ppo_cnn.py
├── train_dqn_cnn.py
├── train_dqn_multi.py
├── train_ppo_cnn.py
├── train_ppo_cnn_comm.py
├── train_ppo_cnn_cov.py
├── train_ppo_cnn_lstm.py
├── train_ppo_encoded.py
├── train_ppo_mlp.py
├── train_ppo_mlp_cov.py
└── train_ppo_multi.pyRunning Experiments for Hypothesis Testing
Hypothesis 1: Effectiveness of RL vs. Greedy Algorithms
To run the experiments for Hypothesis 1:
# Train PPO with CNN for base scenario
python train_ppo_cnn.pyModify dispersion_inc parameter to 0.05 in the script and run again.
# To test the trained algorithms:
python test_trained_search.py --checkpoint <path/to/trained_checkpoint>Optional flag --see can be added to visualize the algorithm in action and make a recording of the simulation.
Hypothesis 2: Centralized vs. Decentralized PPO
To test the centralized versus decentralized performance:
# Train decentralized PPO with CNN
python train_descentralized_ppo_cnn.pyHypothesis 3: Impact of Communicating Target Trajectory
To evaluate the effect of trajectory communication:
# Train PPO with trajectory data
python train_ppo_cnn_comm.py
# Train PPO with LSTM for sequence handling
python train_ppo_cnn_lstm.py
# To test the models:
python test_trained_cnn_lstm.py --checkpoint <path/to/trained_checkpoint>
python test_trained_search_comm.py --checkpoint <path/to/trained_checkpoint>Hypothesis 4: Multi-Target Handling by RL Algorithms
To replicate multi-target search scenarios:
# Train PPO with MLP for coverage
python train_ppo_mlp_cov.py
# Test the trained algorithm
python test_trained_cov_mlp.py --checkpoint <path/to/trained_checkpoint>Hypothesis 5: Efficiency and Prioritization in Coverage
To conduct tests related to coverage efficiency:
TIP
Remember to modify the person_amount parameter in the environment setup within train_ppo_cnn.py to 4.
# Modify `person_amount` to 4 in the environment setup within `train_ppo_cnn.py`
python train_ppo_cnn.py
# Test the model as described in Hypothesis 1
python test_trained_search.py --checkpoint <path/to/trained_checkpoint>Conclusion
These instructions provide a comprehensive guide on how to set up and run experiments for each hypothesis. Ensure that all dependencies are installed and environment variables are set correctly before running the scripts. Happy experimenting!
Stay Updated
We appreciate your patience and interest in our work. If you have any questions or need immediate assistance regarding our algorithms, please do not hesitate to contact us via our GitHub Issues page.
License
This documentation is licensed under the terms of the MIT License. See the LICENSE file for more details.